问题描述
年初公司某业务间隔发生业务中断问题,因为该业务实时性要求非常高,业务端对中断非常敏感,后端的同学排查了很长时间,一直没有定位到问题,所以我也介入进来协助定位问题
首先描述下问题,在随机的时间点,业务系统会出现大量的Rds Redis、Rds MySQL以及RabbitMQ连接超时,造成业务系统中断
背景介绍
现有的系统构建在阿里云,系统架构为SLB+ECS+Rds,ECS有3台,3台ECS都出现过上述问题,每次出现的时间和ECS主机都随机,也并没有和业务高峰的出现相关
因为业务在快速发展,性能压力也在日益增加,后端的同学最开始排查问题的关注点是业务代码以及Redis和MySQL的负载。业务代码经过排查,没有发现明显问题,Redis和MySQL的负载也并不高
按照后端同学的排查路径,首先检查了下MySQL和Redis的负载情况,连接数没有异常,CPU和内存占用也无异常,另外在其中一台ECS主机出现上述现象的同时,另外两台ECS主机和Redis以及MySQL的连接正常,初步怀疑是出问题的ECS主机网络出现问题,很像是网络抖动,中断了网络连接
之前运维有提交工单,提交了我们的疑虑,阿里云的工程师回复在问题ECS主机抓包

排查过程
网络抓包
因为问题都是随机出现,我们并不确定什么时间在哪一台ECS会出现上述问题,所以我们对所有的ECS主机做抓包处理,又因为抓包文件非常大,另外购买了500G的nas用来存储抓包文件
附上抓包脚本,供有需要的同学参考
nohup tcpdump -i eth0 host ! 192.168.6.225 -s0 -G 600 -w ./tcpdumplogs/1_%Y%m%d%H%M%S.pcap &
192.168.6.225是nas的地址,抓包的时候去掉此IP相关信息,否则抓包信息会重复
然后只能干等,因为我们也不知道什么时间才会出现问题
怀着焦急的心情经过若干天之后,又出现了该问题,下面是现象和抓包文件分析
网络抓包情况说明
现象描述
- 上午10:19分左右程序发现连接Rds MySQL云数据库抛出timeout报警,只在当前ECS主机发现
- 上午10:19分左右程序发现连接Redis云数据库抛出timeout报警,只在当前ECS主机发现
Tcpdump抓包文件分析
上午10:18:50.528567到上午10:18:50.591897这段时间内服务端程序发送的网络包全部丢失,造成所有的网络连接被客户端rst重置
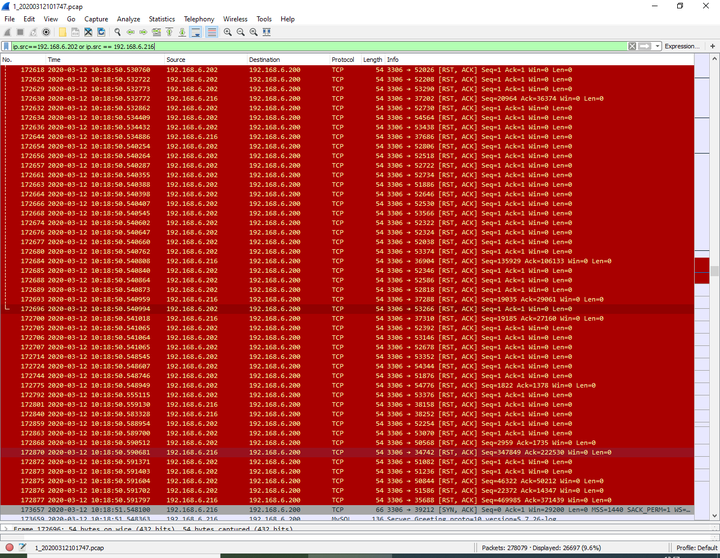
Rds MySQL断开情况
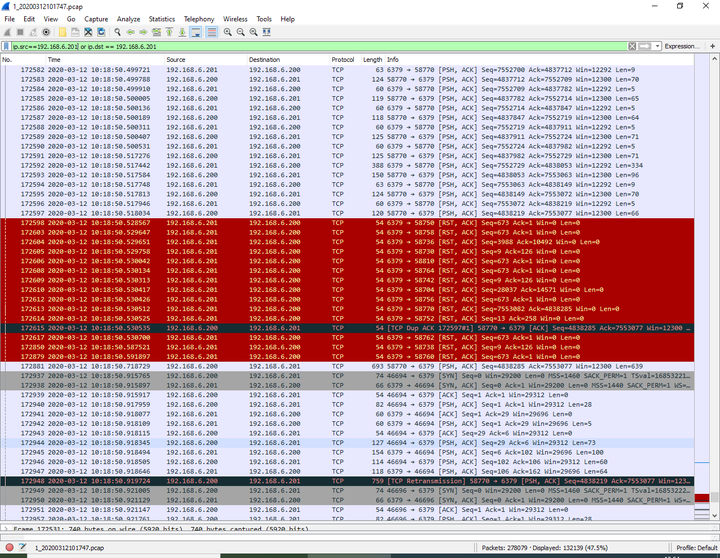
Redis断网情况
这样看网络基本是一个时间点断开,抓包文件也提交给了阿里云,初步怀疑ECS出问题的概率比较高
然后,阿里云的回复是他们需要进ECS进行故障排查

授权后阿里云的回复
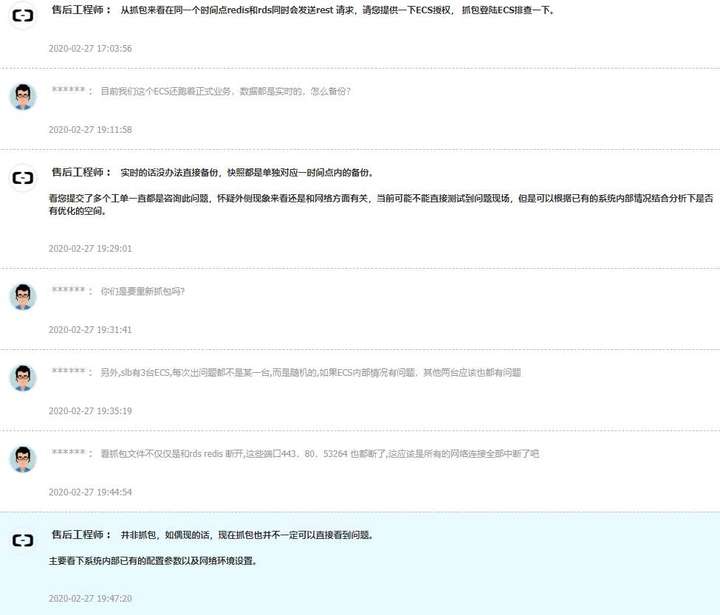
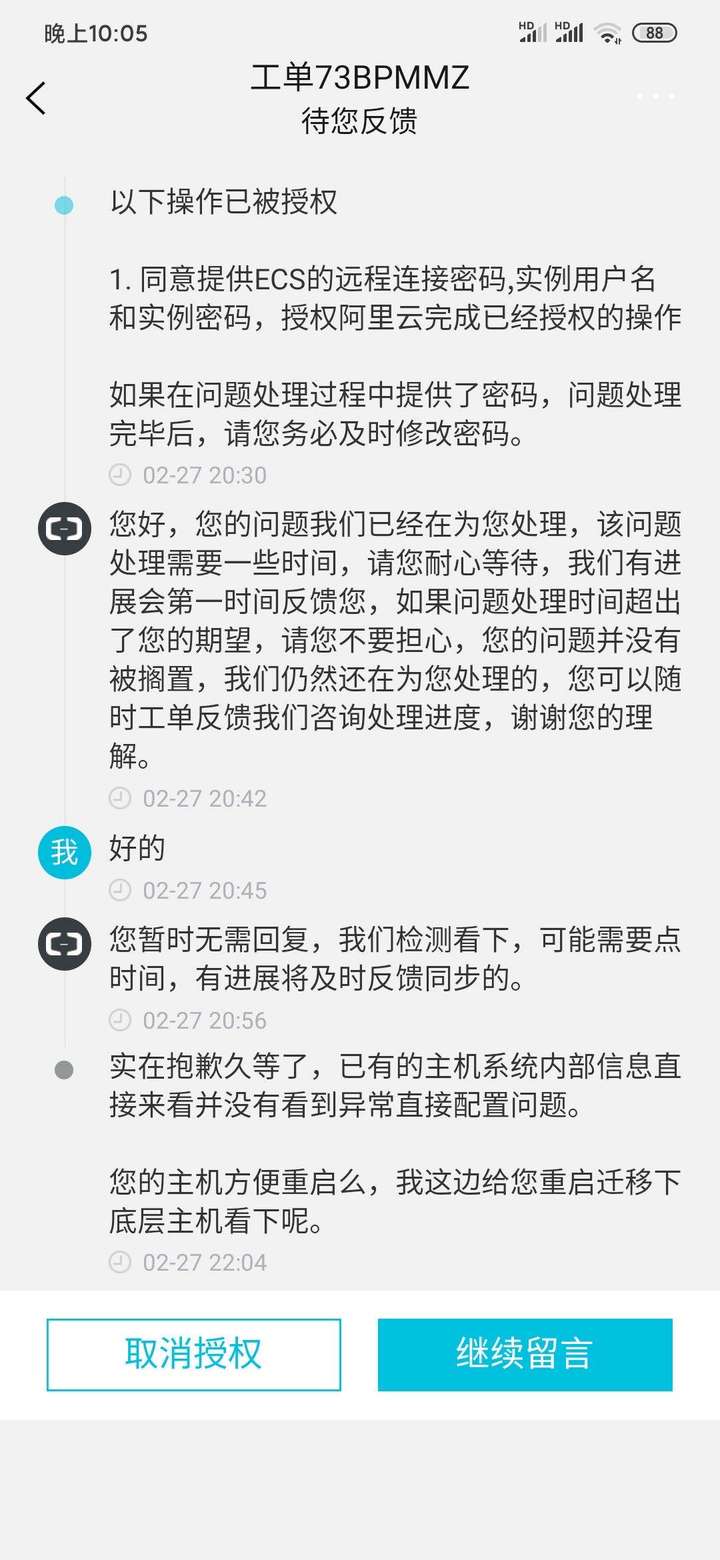
临时方案
底层主机迁移

然后迁移完底层主机之后,又观察了一段时间,在我们都以为没问题的时候,问题又复现了,真真真崩溃。
还是大量的连接被rst,怀疑是这样的流程 服务端发了一个ack,在ack发送的时候网络有问题了,客户端认为服务端断网了,回收当前连接,服务端没有感知断网,闪断完继续发送ack,客户端接收到ack,但是连接已经回收,就按这个ack回了一个rst,让服务端回收连接资源,客户端然后重新发了一个新的连接请求。
越发感觉是ECS主机的问题,但是阿里云那边一直让我们排查代码,我们基本属于束手无策了,突然阿里云回复了信息,出问题的ECS底层出现异常,然后又自动恢复了(后来和阿里云的核心开发人员沟通,是ECS主机发生了热迁移,所有连接被强制rst了)
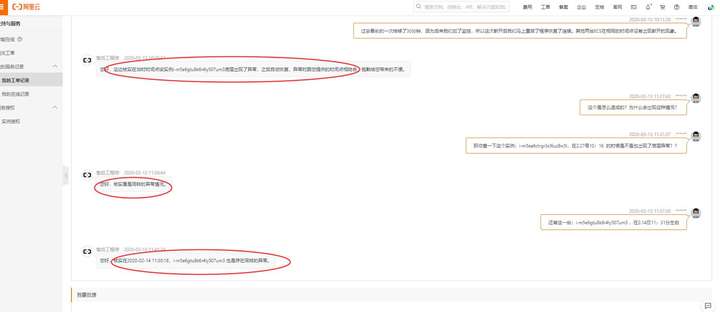
问题定位
然后为了解决这个问题,阿里云的产品经理拉了个钉钉群讨论解决方案,阿里云的解释如下:
从文档和pcap来看:
1. 整个链路是: 公网client --> SLB --> RS (i-m5e6gtu8k6r4ly507um3) --> rds/redis
2. 文档里的reset 有两类:
(1) rds/redis 发往 i-m5e6gtu8k6r4ly507um3 的 reset包
(2) 公网client 发往 i-m5e6gtu8k6r4ly507um3的reset包
上面两类reset报文,都是符合保护迁移操作的预期
3. 从客户业务的网络模型来看, 需要客户程序具备:
(1) 公网client程序, 具备 重连slb的能力
(2) rs服务程序,具备重连redis/rds的能力
4. 从pcap来看,没有发现 公网访问slb、rs访问redis/rds,有中断30分钟以上的情况,
需要跟确认下,3.12日 i-m5e6gtu8k6r4ly507um3 是否有中断30分钟以上的问题
5、 从后台统计来看, 3月12日 10: 19 自动完成了一次保护迁移,10:19 -- 10:24之间 有公网client 访问 i- m5e6gtu8k6r4ly507um3 的请求;
但10:24 -- 10:58 之间 没有公网client 访问 i-m5e6gtu8k6r4ly507um3, 业务层面在这2个时间点是否有发生什么异常或做了什么 操作?
虽然热迁移只用了几秒钟,但是我们这边业务恢复大概用了30分钟左右
按照阿里云的回复是只要业务程序具备重连就可以了,可是对于我们来讲,只是重连的话我们是具备这个能力的,不过因为连接被强制断开,造成的数据不一致问题需要花费更长的时间来恢复,另外后端的同学也并没有考虑业务重试的问题,如果按阿里云的说法,我们肯定需要花费大量的时间来做程序改造
解决方案
经过几轮沟通,同时和阿里云的同事也进行了一次电话会议,和阿里云的产品和技术同学也达成了技术解决方案
大致的方案如下:
我司的几台ECS主机加入黑名单,除非出现致命的硬件问题,需要做ECS迁移,其它非必须的热迁移都不做迁移处理
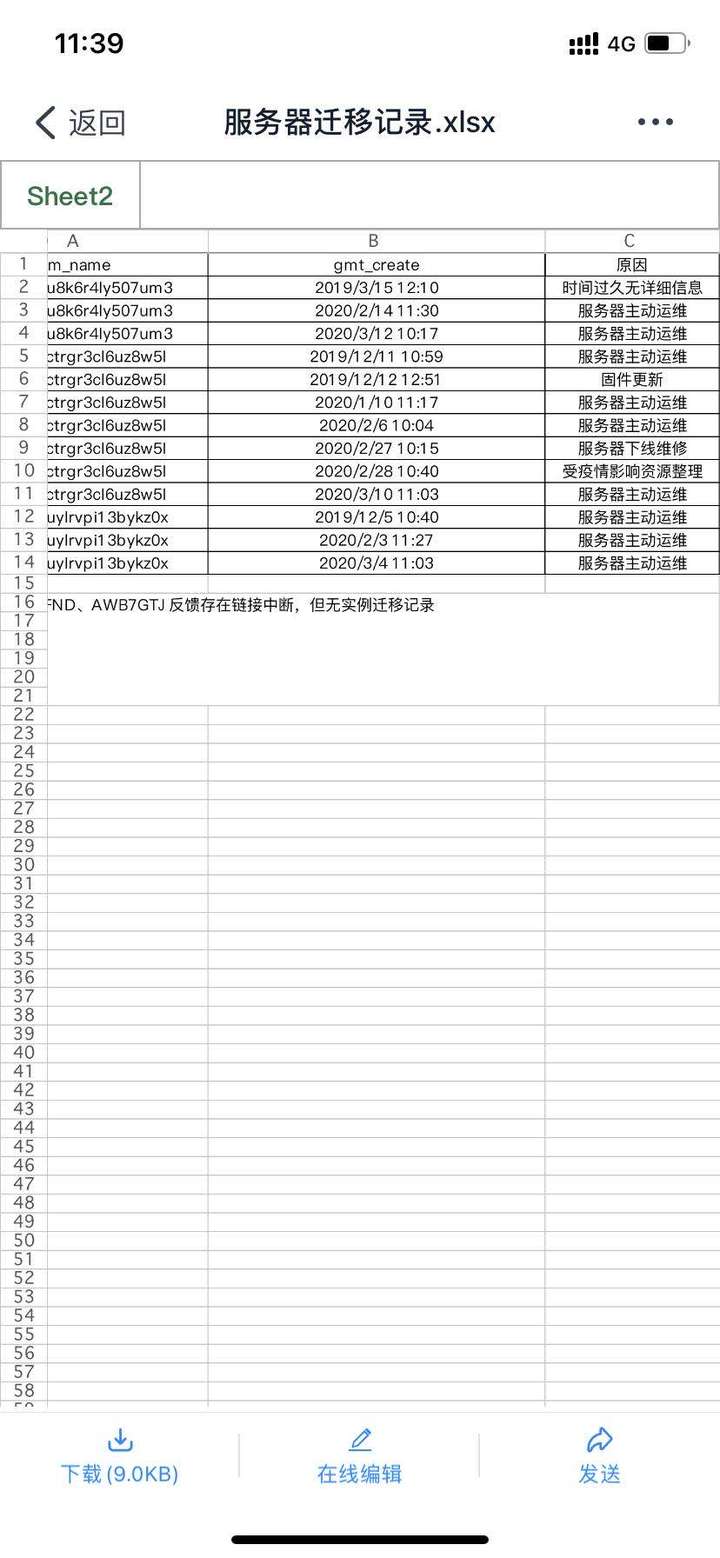
最终处理完成,经过这几个月的运行,没有再次发生网络闪断的问题,然后根据我们的要求,阿里云提供了迁移记录
不过最终的解决方案还是需要我们的后端服务做业务自动重试,这是个漫长的改造过程
问题总结
总结下问题,按照阿里云的开发人员的说法,迁移保护一直都在发生,只要出现迁移保护,所有的连接都会被强制断开,如果阿里云的售后工程师早点告知我们平台具有此项特性,也就没有这么长时间的排查
另电话会议中我们也提了认为合理的产品建议,如果迁移保护不可避免,那么阿里云的产品如果支持不强制断开所有连接的方式进行迁移,对于后端的开发人员来讲,就更加的友好了,也希望阿里云的ECS产品可以早日具备此项特性